
Refactoring data pipelines with LLMs
Notes from a SSIS to dbt migration
Data pipelines eventually need refactoring: source or target systems evolve, the underlying technology becomes obsolete, or performance no longer matches current volumes. Rewriting them by hand is rarely viable, but LLM coding assistants now make full pipeline refactoring tractable, provided they are wrapped in a disciplined workflow. Drawing on a large-scale SSIS to dbt code migration covering around a thousand stored procedures and a hundred SSIS jobs, this article describes three practices that turn an LLM from clever autocomplete into a reliable refactoring partner: anchoring every change to an equivalence test against the legacy output, migrating one business domain at a time, and iteratively engineering the model's context so it stays sharp across long unattended runs.
Why pipeline refactoring becomes unavoidable
Many large SQL Server estates rely on data migration pipelines built with SSIS packages and stored procedures, accumulated over years of incremental changes. The case described here involves a migration pipeline of roughly a thousand stored procedures and a hundred SSIS jobs. As the system aged, the migration code itself became the bottleneck: chained to Microsoft's stack, painful to test, increasingly hard to staff as SSIS expertise thins on the market, and very awkward to handle in a modern Git workflow.
SSIS packages are stored as verbose XML: diffs are unreadable, merges are difficult to resolve, and code review is nearly impossible. The runtime is tied to one database engine, blocking any future move toward PostgreSQL or another platform that might be required. Running a single test requires building several Visual Studio projects and their dependencies up front. Identical scripts are duplicated across customer repositories with no shared library, and any schema evolution requires manual changes across multiple components of the migration chain.
Why dbt was the target architecture
We chose to rewrite the migration pipeline in dbt. It addresses these pain points by design: Git-native, declarative DAG orchestration with auto-detected lineage, easy-to-enable per-developer schema isolation, native test support at the framework's core, auto-generated documentation, broad compatibility across database engines, and a package system that lets a shared core be reused across customers with per-customer overrides.
Why volume changed the equation
A literal rewrite of around a thousand stored procedures and a hundred SSIS jobs, by hand, was not realistic on any acceptable timeline, and any silent regression would translate into data quality loss in the migrated records. This is where LLM assistance changed the equation.
Three practices that made the LLM effective
Three practices made the use of an LLM (here, Claude Code) effective in that context.
1. Equivalence is the contract
Every dbt model produces a dataset that is compared row by row with the output of the legacy stored procedure it replaces. This comparison is the cornerstone that orients the LLM: the test result, not subjective review, tells the model whether its implementation is correct.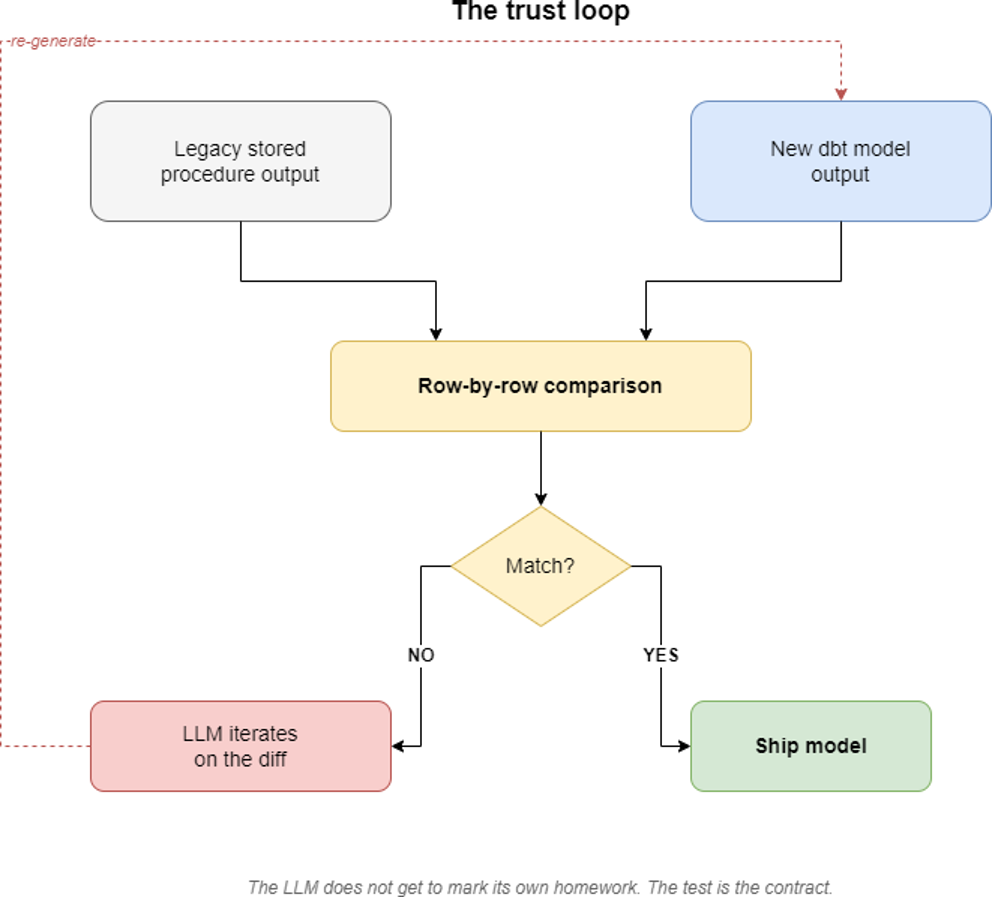
2. One business domain at a time
Migration proceeds one functional area of the legacy system at a time, each shipped independently.
3. Engineer the context iteratively
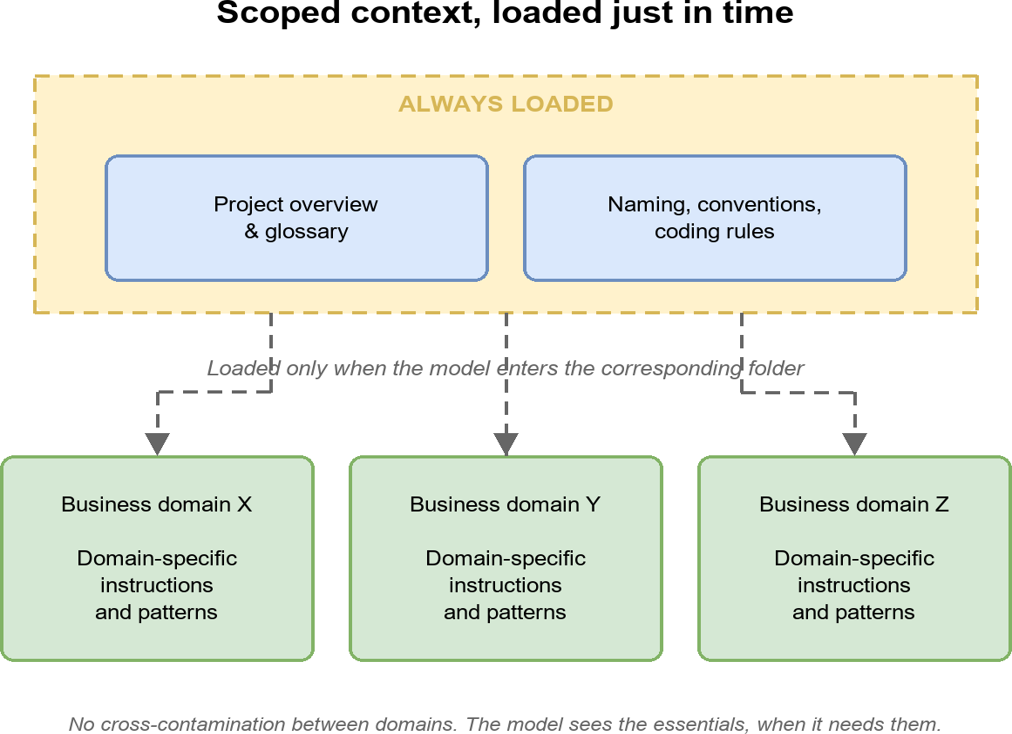
After each successful business domain we refined the project's instructions: a domain-specific skill encoding the migration workflow, a hierarchy of scoped instruction files attached to each business domain folder so the model only ever sees the rules and patterns that apply to the domain being migrated, and a set of rules pruning what gets loaded at any given moment. The model retrieves the context it needs only when it needs it, and only the essentials, so it stays sharp on the task at hand. A shared memory file, versioned in Git, carries non-obvious lessons across sessions and across the team. The aim is straightforward: make the model perform better with every new domain it touches.
Take-away
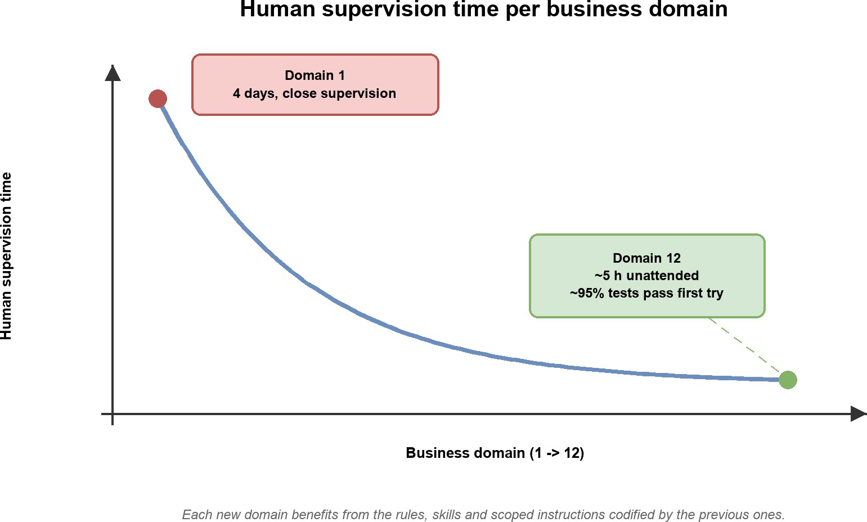
The compound effect is striking. The first domain took four days of close supervision. By the twelfth, the workflow runs five hours unattended on a new domain and lands at an implementation that passes about 95% of its equivalence tests on the first try. A data engineer still owns the last mile: reviewing edge cases, reconciling deliberate divergences from the legacy behaviour, and signing off on the validation suite. But the role has shifted from translation to judgment.
The valuable outcome is not only the SSIS to dbt rewrite timeline. The output is a modern, documented, tested codebase, no longer chained to a single database vendor. The methodology generalises beyond this project: any legacy SQL pipeline whose old version can still be run long enough to capture reference outputs becomes a candidate. The LLM is the lever, but equivalence testing, decomposition, and context engineering are the foundation.